Weaviate
Quick Summary
Weaviate is a cloud-native, open-source vector database that uses state-of-the-art ML models to embed data. It is fast, flexible, and designed for production-readiness, capable of performing 10-NN nearest neighbor searches on millions of objects in milliseconds.
To learn more about leveraging Weaviate as your retrieval engine, visit this page.
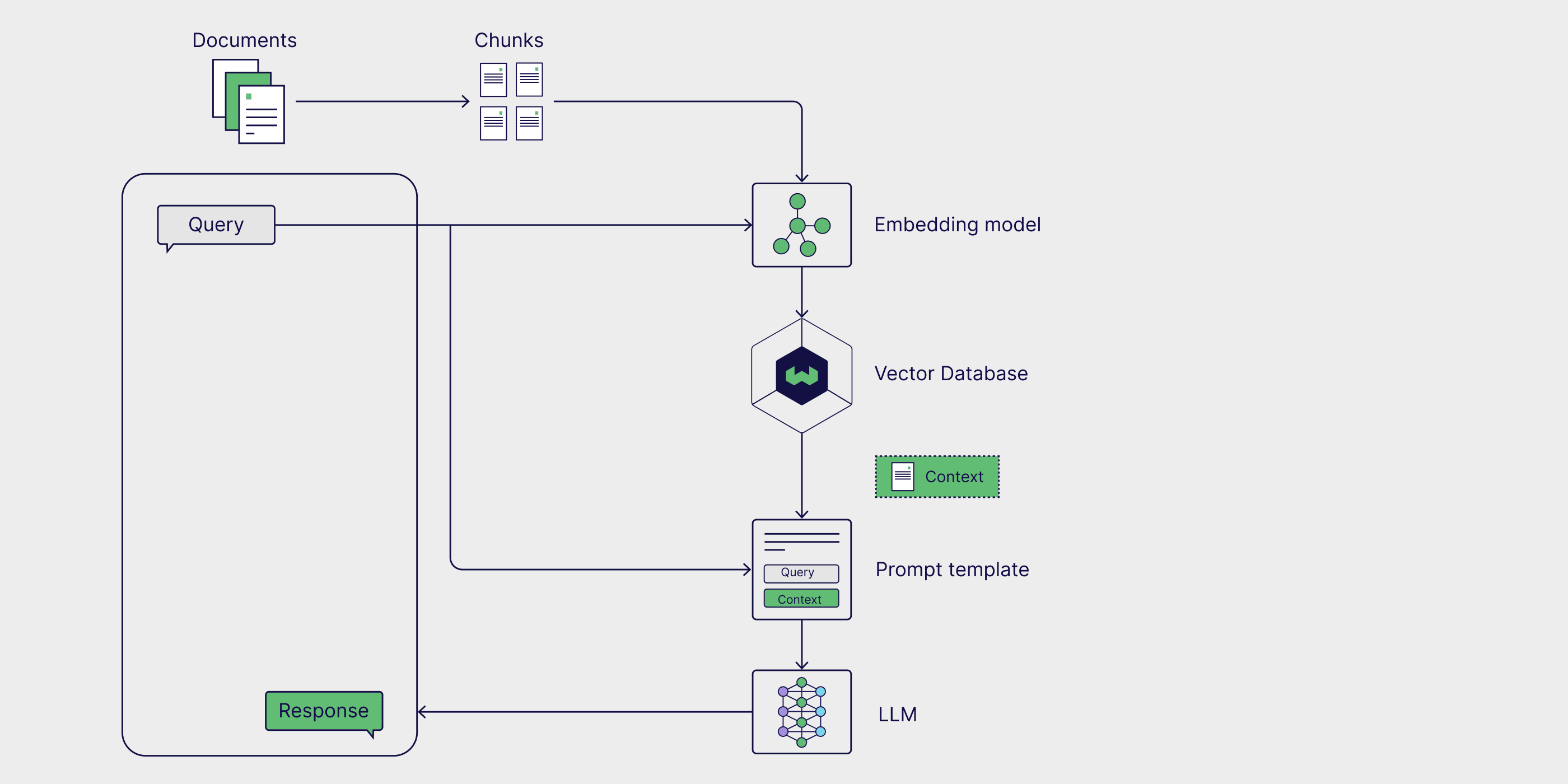
Youn can easily evaluate your Weaviate retriever with DeepEval to find the best hyperparameters for your Weaviate engine. This parameters include with_limit (top-K) and vectorizer (embedding model), among many others.
You can quickly get started with Weaviate by running the following command in your CLI:
pip install weaviate-client
Setup Weaviate
To start using Weaviate, establish a connection to your local or cloud-hosted instance by initializing a Weaviate client and configuring authentication with your API key.
import weaviate
import os
client = weaviate.Client(
url="http://localhost:8080", # Change this if using Weaviate Cloud
auth_client_secret=weaviate.AuthApiKey(os.getenv("WEAVIATE_API_KEY")) # Set your API key
)
To enable efficient similarity search, define a Weaviate schema that stores documents with a text property for raw content and an associated vector for embeddings. Since Weaviate supports both internal and external vectorization, this schema is configured to use an external embedding model.
...
# Define the schema
class_name = "Document"
if not client.schema.exists(class_name):
schema = {
"classes": [
{
"class": class_name,
"vectorizer": "none", # Using an external embedding model
"properties": [
{"name": "text", "dataType": ["text"]}, # Stores chunk text
]
}
]
}
client.schema.create(schema)
Before adding documents to Weaviate, convert text into vector representations using an embedding model. We'll be using all-MiniLM-L6-v2 from sentence_transformers.
Using an external embedding model ensures flexibility in choosing the most suitable representation for your data, which can be important if your Weaviate engine is struggling to score well on metrics like Contextual Precision.
...
# Load an embedding model
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
# Example document chunks
document_chunks = [
"Weaviate is a cloud-native vector database for scalable AI search.",
"Weaviate enables fast semantic search across millions of vectors.",
"It integrates with external embedding models for custom vectorization.",
...
]
# Store chunks with embeddings
with client.batch as batch:
for i, chunk in enumerate(document_chunks):
embedding = model.encode(chunk).tolist() # Convert text to vector
batch.add_data_object(
{"text": chunk}, class_name=class_name, vector=embedding
)
Evaluating Weaviate Retrieval
Once the Weaviate retriever is set up, we can begin evaluating its effectiveness in returning relevant contexts. This involves:
- Constructing a Test Case: to do so, define an
inputquery that represents a typical search scenario and prepare the expected output. Then generate theactual_outputfor the given input and extract the retrieved context during generation. - Evaluating the Test Case: simply run deepeval's
evaluatefunction on your populated test case and selection of retriever metrics.
Preparing your Test Case
The first step in generating the actual_output from your RAG pipeline is retrieving the relevant retrieval_context from your Qdrant collection based on the input query. Below is a function that encodes the query, searches for the top 3 most relevant vectors in Qdrant, and extracts the corresponding text from the retrieved results.
...
def search(query):
query_embedding = model.encode(query).tolist()
result = client.query.get("Document", ["text"]) \
.with_near_vector({"vector": query_embedding}) \
.with_limit(3) \
.do()
return [hit["text"] for hit in result["data"]["Get"]["Document"]] if result["data"]["Get"]["Document"] else None
query = "How does Weaviate work?"
retrieval_context = search(query)
Next, incorporate the retrieved context into your LLM's prompt template to generate a response.
prompt = """
Answer the user question based on the supporting context.
User Question:
{input}
Supporting Context:
{retrieval_context}
"""
actual_output = generate(prompt) # Replace with your LLM function
print(actual_output)
With both the actual_output and retrieval_context generated, we now have all the necessary parameters to construct our test case:
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input=input,
actual_output=actual_output,
retrieval_context=retrieval_context,
expected_output="Weaviate is a powerful vector database for AI applications, optimized for efficient semantic retrieval.",
)
Before proceeding with the evaluation, let's examine the generated actual_output.
Weaviate is a cloud-native vector database that enables fast semantic search using vector embeddings and hybrid retrieval.
Running Evaluations
To evaluate an LLMTestCase, define the relevant retrieval metrics and pass them into the evaluate function along with the test case.
from deepeval.metrics import (
ContextualRecallMetric,
ContextualPrecisionMetric,
ContextualRelevancyMetric,
)
from deepeval import evaluate
...
contextual_recall = ContextualRecallMetric(),
contextual_precision = ContextualPrecisionMetric()
contextual_relevancy = ontextualRelevancyMetric()
evaluate(
[test_case],
metrics=[contextual_recall, contextual_precision, contextual_relevancy]
)
Improving Weaviate Retrieval
Once you've evaluated your Weaviate retriever, it's time to analyze the results and fine-tune your retrieval pipeline. Below are example evaluation results from more test cases.
| Query | Contextual Precision | Contextual Recall | Contextual Relevancy |
|---|---|---|---|
| "How does Weaviate store vector data?" | 0.62 | 0.95 | 0.50 |
| "Explain Weaviate's indexing method." | 0.55 | 0.89 | 0.47 |
| "What makes Weaviate efficient for search?" | 0.68 | 0.91 | 0.53 |
- Contextual Precision is suboptimal → Some retrieved contexts might be too generic or off-topic.
- Contextual Recall is strong → Weaviate is retrieving enough relevant documents.
- Contextual Relevancy is inconsistent → The quality of retrieved documents varies across queries.
Each metric is impacted by specific retrieval hyperparameters. To understand how these affect your results, refer to this RAG evaluation guide.
Improving Retrieval Quality
To enhance retrieval performance, experiment with the following Weaviate hyperparameters:
Tuning
with_limit(Top-K retrieval)- If precision is low, reduce
with_limitto retrieve fewer but more accurate results. - If recall is too high with irrelevant results, adjust
with_limitto balance quantity and quality.
- If precision is low, reduce
Optimizing
vectorizer(embedding model)- Test alternative embedding models for better domain-specific retrieval:
BAAI/bge-small-enfor ranking improvements.nomic-ai/nomic-embed-text-v1for retrieving longer-form documents.msmarco-distilbert-base-v4for passage retrieval.
- Test alternative embedding models for better domain-specific retrieval:
Implementing Hybrid Retrieval (Vector + BM25)
- If Weaviate’s pure vector search isn’t retrieving precise matches, combining vector search with BM25 keyword retrieval can help.
Applying Advanced Filtering (
nearText,whereconstraints)- Leverage metadata-based filtering to refine search results and remove less relevant chunks.
Experimenting With Different Configurations
To systematically test variations in retrieval settings, run multiple test cases and compare contextual metric scores.
# Example of running multiple test cases with different retrieval settings
for vectorizer in ["all-MiniLM-L6-v2", "bge-small-en", "nomic-embed-text-v1"]:
retrieval_context = search(query, vectorizer)
test_case = LLMTestCase(
input=query,
actual_output=llm.generate(query, retrieval_context),
retrieval_context=retrieval_context,
expected_output="Weaviate is an optimized vector database for AI applications.",
)
evaluate([test_case], metrics=[contextual_recall, contextual_precision, contextual_relevancy])
Tracking Improvements
After tuning your Weaviate retriever, monitor improvements in Contextual Precision, Contextual Recall, and Contextual Relevancy to determine the best hyperparameter combination.
For structured tracking of retrieval performance and hyperparameter comparisons, Confident AI provides real-time evaluation analysis.